
So what is Natural Language Processing (NLP) all about ? NLP basically enables people to interact with the connected devices in a very normal everyday language that responds accordingly. Thus creating a value in the lives of the people.
This particular research paper "A large annotated corpus for learning Natural Language Inference(NLI)" is quite an impressive research made by the folks at Stanford university. I'll try to be explaining in a very plain english so the amazing content can be easily deciphered to you.
So let's get started! As we all know that in machine learning even more important than the algorithm or the models that we are using is our data set , or to be more specific the quality of the data set. For so long the research in NLP has been affected just because of the same reason that we had limited amount of resources(data) that were available in order to train our model sufficiently that is then better able to interpret the meaning of the sentences more accurately. No matter there are already available corpuses trying to do with it's purpose but there are some problems associated with it. Before we talk about the problems that are associated. Let's first just have a look at the alredy available corpuses for NLI.
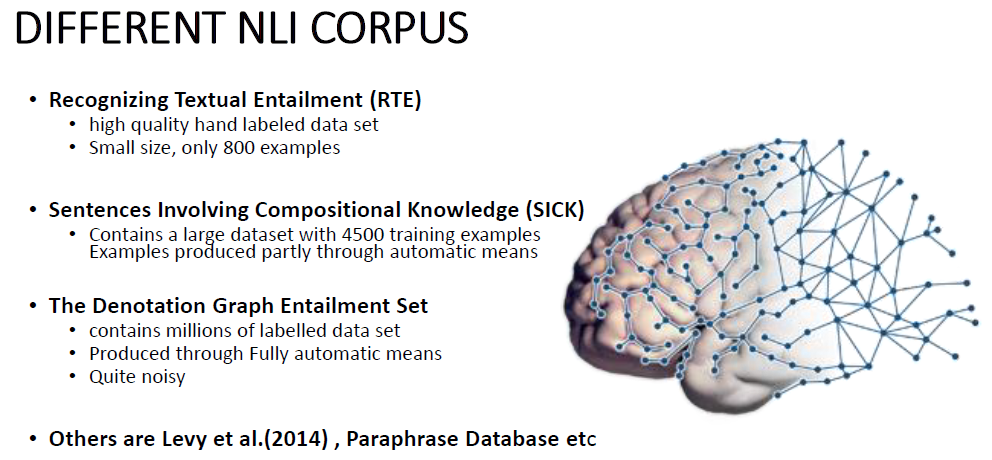
Generally the problem with the above datasets is that they donot consists of sufficient sentence examples for Machine Learning model training and secondly most of these datasets consists of examples that are artificially produced. Artificially produced? yes, the sentence examples which are constructed automatically using algorithums. So because of this, it infuse some spurious patterns within the dataset which is actually damaging for the model training process in machine learning.
As you can see in the SICK data set, some of the examples are artifically produced whereas the Denotation Graph Entailment set, almost all of the sentence are constructed in that manner which makes the dataset quite noisy. RTE data set on the other hand, though is genuinely constructed using hand labeled examples but consists of only 800 examples!
So, due to these limitations, there are there are basically two problems that arises when these corpuses are used to train the models in ML for sentence meaning predictions. These are:
1-) Indeterminacies of the event
2-) Entity Coreference
Let's understand these two problem terminologies with a set of examples

For example, consider the above two sentence example pairs. If it is assumed that both these sentences 'A boat sank in the Pacific Ocean' and 'A boat sank in the Atlantic Ocean' are part of a single event, then these two examples will be labelled as 'contradiciton' as pacific and atlantic are two distinct oceans and shall contradict together. BUT, if it is assumed that both these sentences are not part of a single event but two separate events, then these sentence pair shall be labelled as 'neutral'.
So which one is the final correct label?
If we try to make the computer understand that okay no, these two sentences are part of separate events, then in the other sentence meaning predictions, contradictions are only going to appear where there is broad universal assertion. On the other hand, if we try to make the computer understand that okay no, these two sentences are part of the same event that contradictions would appear on even like simple sentences as in "Donald Trupm is the president of USA' and ' I had sandwich for lunch today'.
So you see, here is the circle of problem, no matter you go here or there you are trapped.
Now taking another example for the second problem associated with these corpuses.

For these two sentence example pair again, if both these sentences 'A tourist visited NewYork' and ' A tourist visited the city' are considered to be the part of the single event than the entity NewYork and city would justify the pair to be an 'entailment' (meaning an accurately related sentences). However, if these are considered part of the single event, then the two sentences would be marked as 'contradiction'!.
So, how do we get out of this mess?
Introducing Stanford Natural Language Inference (SNLI) Corpus.
This corpus addresses for the issues of size, quality and indeterminacy.
It has two unique attributes
1)Collection of a bank of large sets of sentence pairs, 570,152 example sentence to be exact!
2)All of the sentences and labels are written by human!
So this makes it a very naturally generated genuine and reliable dataset on which to train your model! :)
Data Collection
•Data was collected using a crowdsourcing framework•Participants were given a sentence and were instructed to produce 3 hypothetical sentences (as shown on right)
Following image shows the instructions participants were given:

Validation
•Validation was made on 10% of the data
•Labels were given to each sentence pair through 4 different annonators
Following image shows the labels given to sentence pair by the annonators. First four labels are given by 4 annonators and the fifth label is the label given by the author of the sentence.

Validation Result
Following are the much satisfying validation results achieved from the data tested:

SNLI as a platform for model evaluation!
The most immediate application of this corpus is for developing models for the task of NLI. In particular, since, it is dramatically larger than any other corpus of comparable quality, we expect it to be suitable for training parameter-rich models like neural networks which have not been previously competitive in this task
The performance of three classes of models we explored
1) Excitement Open Platform from NLI System
2)Lexicalized Classifiers
3)Distributed representation Models (including baseline model & neural network sequence models)
A learning curve for the feature based models of lexicalized, unlexicalizedand Long Short-Term Memory were drawn

Analysis
•LSTM and Lexicalized model show similar performance when trained on full SNLI corpus
•Somewhat steeper slope of LSTM hints for its ability to learn arbitrary structure representations of sentence meaning better
•The curve shows overall that the large size of corpus is crucial to both Lexicalized and LSTM model
Transfer Learning with SICK Dataset & results
Last thing done was transferring the learning with SICK dataset and competitive results were achieved!
First, the parameters of LSTM RNN model was trained on SNLI dataset to initialize a new model and then tested on SICK data. This however showed poor performance, labelling more neutral examples as contradictions
But then,
SNLI representation was transferred to SICK data and then tested. This showed a 84.6% level of interannonatoragreement representing the highest level ever achieved!
This has been the performance ceiling according to the paper, and no model has yet been able to show such a strength in accurately determing the meaniing of newly sentence structures as this.
Conclusion
Natural Languages are powerful vehicles for for reasoning and almost all of the questions related to the meaningfulness in the sentence can be reduced if the question to the sentence entailment and contradictions are addressed in the context. This paper seek to remedy the shortcomings of the other corpuses by providing a large database and all naturally hand labelled data set. The corpus was then used to evaluate a range of models. It was found that simple LSTM model and neural network model performed well.
Hope you got a good insight literature review of this paper. The corpus is all open source. You can have a hand on for the following link! :)
Cheers!
By: Kanza Batool Haider
 If you enjoyed this post and wish to be informed whenever a new post is published, then make sure you subscribe to my regular Email Updates.
Subscribe Now!
If you enjoyed this post and wish to be informed whenever a new post is published, then make sure you subscribe to my regular Email Updates.
Subscribe Now!



0 comments:
Leave your feed back here.